Extracting Data from PDFs: The Ultimate Guide

Why is extracting data from PDFs important?

Every day, organizations handle thousands of PDF documents—invoices, contracts, reports, and forms. PDFs are reliable tools for exchanging information. However, extracting data from them can be difficult. PDFs aim to display content rather than make it easy for users to extract data. If you're new to this, don't worry! This tutorial will explain the causes of the difficulty. It will also address how firms can achieve successful management of it.
Why is PDF data extraction difficult?
Here are the primary reasons why working with PDFs can be difficult:
- Built for Display, Not Data: PDFs aim for visual appeal, not structure. A table may look great. But, it may be a picture or scattered text. This makes it hard to copy or process it.
- Scanned PDFs: Some PDFs contain scanned images of paper documents. Use OCR software to turn the photos into text. Yet, poor-quality scans can result in inaccuracies.
- Different formats: each PDF is unique. One document's layout may show a marked difference from another's. This makes it hard to use the same tool or technique on all files.
A Practical Approach: Focus on What Matters.
Instead of trying to extract everything, focus on the data you need. Here's how some teams prioritize their efforts:
- Accounting: Retrieve invoice numbers, dates, and payment amounts.
- Legal: Extract keywords, dates, and names from contracts.
By restricting your focus, you can simplify the process and achieve greater outcomes.
Success Stories: Real-world Benefits
Here's how businesses profit from improved PDF data extraction.
- Faster Processing: Automating chores such as invoice processing saves hours of manual labor.
- Better accuracy: Clean, structured data enables teams to make better decisions.
These advantages depend on using the right tools and methods. A generic, one-size-fits-all solution often leads to frustration. Instead, use procedures relevant to your document types.
Why is manual data entry outdated?
Extracting data from PDFs often relies on manual data entry, which creates major bottlenecks and wastes valuable time. Forward-thinking companies are discovering significant benefits by moving away from manual processes to automated solutions. This shift allows teams to focus on more valuable work instead of tedious data entry tasks.
Automating Benefits
- Saves time: Automating repetitive processes can cut processing time by up to 85%.
- Manual entry has a 5-10% error rate. Automated tools can achieve 99% accuracy.
Identifying Automation Opportunities
Tasks involving vast amounts of structured data are great candidates for automation. Examples include extracting invoice information such as amounts, dates, and numbers.
- Processing forms with a consistent design.
- For complex or inconsistent materials, a human may need to verify the results.
Maintaining Quality at Scale
Maintaining accuracy becomes more important as firms expand. To do this:
- Use tools that can handle a variety of document types.
- Include automated checks to detect typical problems.
To assure quality, conduct occasional manual reviews.
Using AI to Improve Document Data Extraction

AI is transforming the way we extract data from PDFs. By collaborating with standard OCR technologies. AI can better interpret and organize complex data.
Advantages of AI
- AI can recognize and organize text, tables, and images based on context.
- AI tools improve with use, so they need no manual fixes.
Real-world applications
Some businesses use AI to process financial and legal documents. It extracts crucial data points with speed and reliability.
Combining Technologies
Utilizing various AI technologies often produces the greatest results. For example:
- OCR translates scanned images into text.
- Natural Language Processing (NLP) understands and interprets the text’s meaning.
These tools can handle even unstructured data, like text or mixed layouts.
Maximizing Metadata for Better Results

Metadata is like a hidden cheat sheet for your PDFs. It includes information like the document’s creation date, author, and tags. This data can make it easier to find and organize your files.
Metadata Matters
Metadata is important for faster searches and easier content discovery. Better Automation: Tools leverage metadata to process documents with greater efficiency.
How to use Metadata
- Begin by determining which metadata are most relevant for your business.
- Accounting teams may rank client names and invoice numbers.
- Legal teams may rank contract dates and parties.
- Use tools to ensure that your metadata remains consistent across all papers.
Choosing the Right Tools for Your Team
Choosing the ideal tool for your organization is dependent on your requirements. Here's how to get started:
Evaluating Your Needs
Ask yourself: Do your PDFs contain scanned photos or digital files? How much data should you extract? Do you have excellent accuracy?
Key Features to Look For in a PDF Data Extraction Tool
When comparing tools, focus on the following features:
- OCR capability: Required for scanned documents.
- Extraction methods: Include rule-based and AI-powered approaches.
- Output options: Ensure that your systems are compatible (for example, Excel, CSV, JSON).
- Scalability: Can the tool expand alongside your company?
- Security: Use technologies that meet data protection laws, like GDPR and HIPAA.
- Cost and support: Include licenses and ongoing support.
Building Your Extraction Success Strategy
A clear workflow will help you get the most out of your tools and processes.
Defining Your Objectives
Be explicit about what you intend to do. For example:
- Extract key data points from invoices.
- Organizers should arrange contracts to make them easy to search and retrieve.
Designing Your Workflow
Break the procedure into steps.
- Collect PDFs. Determine how we will receive documents (uploads, email, or system integration).
- Choose tools that suit your documents' nature and complexity. Determine how the team will use the extracted data (e.g., reports, analytics).
Quality Control Measures
- Automated validation and periodic reviews will help to ensure accuracy.
- Plan for Growth.
- Pick tools that can handle more documents and new formats as your business grows.
Steps for Extracting Data from PDFs Using DigiParser
Here are the steps you need to follow:
- Visit DigiParser.
- If you don't already have an account, create one or log in with your existing credentials.
- Navigate to the Dashboard.
- Create a Parser for your document.
- You can choose from the various options provided to you.
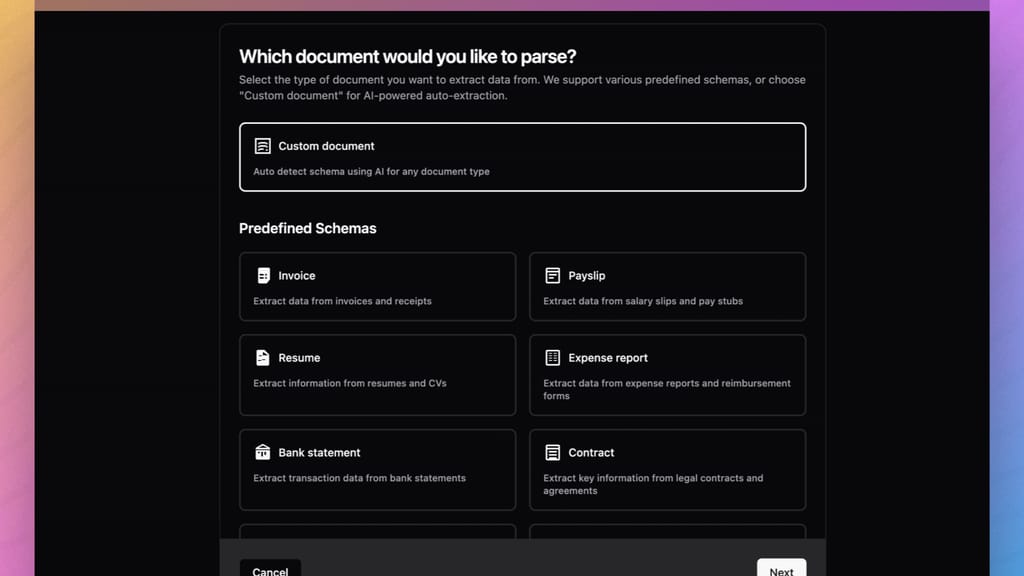
- Highlight or tag important sections of the document (such as invoice numbers, client information, and line items).
- If you plan to process similar PDFs in the future, save the template.
- Click the "Upload" button, then pick the PDF file from which you wish to extract data.
- Confirm the upload to proceed.
- Fill out the fields and table rows according to your specifications.

- Wait as the tool processes the document and extracts structured data.
- View the extracted data in an organised way.
- Validate the output for accuracy. Make changes to templates or settings as needed.
- Export the retrieved data in the format you require. Automation workflows can be integrated using CSV, JSON, Excel, or APIs.
Extracting data from PDFs does not have to be difficult. A clear plan, the right tools, and a focus on your needs can save time, reduce errors, and provide insights. Are you ready to streamline your PDF workflows? Discover how DigiParser can make PDF data extraction simple and effective. Get started with DigiParser now!
Transform Your Document Processing
Start automating your document workflows with DigiParser's AI-powered solution.